
쌓고 쌓다
[SQL] 인덱스 생성 및 제거 본문
PRIMARY KEY를 사용하면 클러스터형 인덱스가, UNIQUE를 사용하면 보조 인덱스가 자동으로 생성되었다.
그 외, 직접 인덱스를 생성하려면 CREATE INDEX문을 사용한다.
인덱스 생성
인덱스를 생성하는 문법을 간단히 하면 아래와 같다.
CREATE [UNIQUE] INDEX 인덱스_이름
ON 테이블_이름 (열 이름) [ASC | DESC]- 이것으로 생성되는 인덱스는 보조 인덱스이다.
- UNIQUE는 중복이 안되는 고유 인덱스를 만드는 것이다. 이때 기존에 입력된 중복이 있으면 X (생략하면 중복 허용)
- 기본은 ASC로 만들어진다.
인덱스 제거
CREATE INDEX로 생성한 인덱스는 DROP INDEX로 제거한다.
DROP INDEX 인덱스_이름 ON 테이블_이름- 기본 키, 고유 키로 자동 생성된 인덱스는 DROP INDEX로 제거하지 못한다.
- ALTER TABLE로 기본 키나 고유 키를 제거하면 자동으로 생성된 인덱스도 제거할 수 있다.
인덱스 제거 할때는 보조 인덱스부터 제거하고 클러스터형 인덱스를 제거하자.
인덱스 생성 실습
현재 member 테이블의 데이터 상태.
USE market_db;
SELECT * FROM member;
member에 어떤 인덱스가 설정되어 있는지 확인.
SHOW INDEX FROM member;
mem_id는 PRIMARY KEY로 설정되어 있으므로 자동으로 클러스터형 인덱스가 적용이 된다.
그래서 Key_name이 PRIMARY이다.
인덱스의 크기 확인.
SHOW TABLE STATUS LIKE 'member';
- Date_length는 클러스터형 인덱스의 크기를 Byte로 표기.
- Index_length는 보조 인덱스의 크기를 표기. 현재 보조 인덱스가 없어 표기 안되어있음.
주소(addr)에 중복을 허용하는 단순 보조 인덱스를 생성해보자.
인덱스의 이름은 idx_member_addr로 지정했다.
CREATE INDEX idx_member_addr ON member (addr);- 보조 인덱스는 단순 보조 인덱스, 고유 보조 인덱스로 나뉜다.
- 단순 보조 인덱스는 중복을 허용한다는 의미.
- 고유 보조 인덱스는 중복을 허용하지 않음.
다시 인덱스의 정보를 확인.
SHOW INDEX FROM member;
Non_unique가 1인걸 보니 중복을 허용하므로 고유 보조 인덱스가 아닌 걸 알 수 있다.
보조 인덱스가 추가되었으니 이제 인덱스의 크기를 다시 확인.
SHOW TABLE STATUS LIKE 'member';
여전히 Index_length가 0이다.
인덱스를 생성하고 적용하려면 아래의 쿼리를 입력해
ANALYZE TABLE문으로 테이블을 분석/처리해야한다.
ANALYZE TABLE member;
mem_number 열에 고유 보조 인덱스를 생성하자.
CREATE UNIQUE INDEX idx_member_mem_number ON member (mem_number);
블랙핑크, 마마무, 레드벨벳의 mem_number가 4로 중복된 값이 있어 에러가 뜬다.
그렇기에 고유 보조 인덱스를 생성할 수 없는 것이다.
회원이름(mem_name)에 고유 보조 인덱스를 생성하자.
CREATE UNIQUE INDEX idx_member_mem_name ON member (mem_name);
여기에 마마무와 이름이 같은 데이터가 들어온다고 하자.
단, 회원 아이디(mem_id)는 다르다.
INSERT INTO member VALUES('MOO', '마마무', 2, '태국', '001', '12341234', 155, '2020.10.10');
고유 보조 인덱스로 인해서 중복된 값을 입력할 수 없기에 오류가 발생했다.
+ 남자, 여자와 같이 성별을 구분하는 열이 있다면 이곳에 인덱스를 생성하면 의미도 없고 오히려 성능에 악영향이다.
왜냐하면 중복된 데이터가 많기 때문이다.
인덱스 활용 실습
현재 회원 아이디(mem_id), 회원 이름(mem_name), 주소(addr) 열에 인덱스가 생성되어 있다.전체를 조회해보겠다.
SELECT * FROM member;이는 인덱스와 아무런 상관이 없다. 왜냐하면 인덱스를 사용하려면 인덱스가 생성된 열 이름이 SQL문에 있어야 한다.

실제로 전체 테이블 검색(Full table Scan)을 했다.
이번에는 인덱스가 존재하는 열을 검색해보자.
SELECT mem_id, mem_name, addr FROM member;
열 이름이 SELECT 다음에 나와도 Full Table Scan이다.
이번에는 인덱스가 생성된 mem_name 값이 '에이핑크'인 행을 조회.
SELECT mem_id, mem_name, addr FROM member WHERE mem_name = '에이핑크';
Single Row(constant)는 인덱스를 사용해서 결과를 얻었다는 의미이다.
즉, WHERE 절에 열 이름이 들어 있어야 인덱스를 사용한다.
이번에는 숫자로 구성된 mem_number에 단순 보조 인덱스를 만들어 숫자의 범위로 조회해보자.
단순 보조 인덱스 생성.
CREATE INDEX idx_member_mem_number
ON member (mem_number);
ANALYZE TABLE member;
조회.
SELECT mem_name, mem_number
FROM member
WHERE mem_number >=7;
인덱스를 사용하지 않을 때 (인덱스가 있어도)
인원수가 1이상인 회원을 조회.
SELECT mem_name, mem_number
FROM member
WHERE mem_number >=1;
아까와 달리 인덱스를 사용하지 않았다.
인덱스가 있더라도 MySQL이 인덱스 검색보다는 전체 테이블 검색이 낫겠다고 판단했기 때문이다.
실제로, 인원수 1이상은 거의 모든 행의 데이터를 가져와야 하므로 인덱스를 왔다갔다하는 것은 비효율적이다.
인원수 mem_number에 2배를 하여 14이상이 되는 데이터를 검색해보자.
SELECT mem_name, mem_number
FROM member
WHERE mem_number*2 >= 14;
이 SQL은 위의 WHERE mem_number >= 7 과 동일한 조건이다.
그런데 mem_number >= 7과 달리 Full Table Scan을 하였다.
이는 WHERE문에서 연산이 가해지면 인덱스를 사용하지 않기 때문이다.
이럴 때 아래와 같이 수정해서 SQL을 사용하자.
SELECT mem_name, mem_number
FROM member
WHERE mem_number >= 14/2;
이번에는 인덱스를 사용했다.
그러므로 WHERE절에 나온 열에는 아무런 연산을 하지 않는 것이 좋다.
인덱스 제거
먼저 인덱스의 이름을 확인하자.
SHOW INDEX FROM member;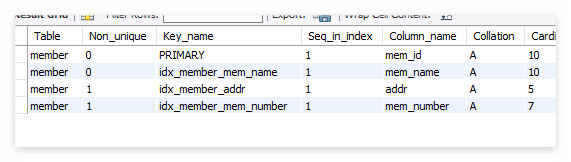
클러스터형 인덱스와 보조 인덱스가 섞여 있다.
먼저 보조 인덱스를 제거하는 것이 좋다.
보조 인덱스는 어떤 것을 먼저 제거해도 상관없다.
DROP INDEX idx_member_mem_name ON member;
DROP INDEX idx_member_addr ON member;
DROP INDEX idx_member_mem_number ON member;
+ 클러스터형 인덱스를 먼저 제거해도 되지만, 데이터를 쓸데없이 재구성해서 시간이 더 걸린다.
기본 키 지정으로 생성된 클러스터형 인덱스를 제거하자.
Primary Key에 설정된 인덱스는 DROP INDEX문으로 제거되지 않고 ALTER TABLE로 제거할 수 있다.
ALTER TABLE member DROP PRIMARY KEY;
이 mem_id열을 테이블 buy가 참조하고 있기 때문에 에러가 뜬다.
기본 키를 제거하기 전에 외래 키 관계를 제거해야 한다.
테이블의 외래 키 이름 조회
information_schema 데이터베이스의 referential_constraints 테이블을 조회하면 외래 키의 이름을 알 수 있다.
SELECT table_name, constraint_name
FROM information_schema.referential_constraints
WHERE constraint_schema = 'market_db';
외래 키 이름은 buy_ibfk_1이다.
이제 외래 키를 제거하고 기본 키를 제거하자.
ALTER TABLE buy
DROP FOREIGN KEY buy_ibfk_1;
ALTER TABLE member
DROP PRIMARY KEY;

말끔히 인덱스가 다 지워졌다.
모든 내용은 '혼자 공부하는 SQL' 도서를 기반으로 학습 후 정리한 내용입니다.
'프로그래밍 > SQL' 카테고리의 다른 글
| [Oracle] SELECT, 합성 연산자(||), DISTINCT, 산술연산, 별명, 정렬, 테이블 구조 (0) | 2022.09.26 |
|---|---|
| [Oracle] 데이터 타입 (1) | 2022.09.25 |
| [SQL] 인덱스(index) (0) | 2022.07.25 |
| [SQL] 뷰(View) (0) | 2022.07.20 |
| [SQL] 고유 키(Unique), 체크(Check), 기본값(Default) 제약조건 (0) | 2022.07.19 |


