
쌓고 쌓다
[SQL] ORDER BY, LIMIT, DISTINCT, GROUP BY, HAVING, 집계함수 본문
ORDER BY
SELECT mem_id, mem_name, debut_date FROM member ORDER BY debut_date;
기본값은 ASC로 오름차순 정렬이다.
여기서 내림차순을 원한다면 DESC를 제일 뒤에다 붙여주면 된다.
SELECT mem_id, mem_name, debut_date FROM member ORDER BY debut_date DESC;
WHERE 절을 ORDER BY 절 앞에 추가하여 함께 사용할 수 있다.
height가 164보다 큰 조건을 추가하였다.
SELECT mem_id, mem_name, debut_date FROM member WHERE height >=164 ORDER BY debut_date DESC;

정렬 기준은 여러 개도 가능하다.
정렬 기준이 1개고 같은 값이 존재한다면 또 다른 정렬 기준을 통해 같은 값을 같은 자료를 다른 기준으로 정렬할 수 있다.
SELECT mem_id, mem_name, debut_date FROM member WHERE height >=164 ORDER BY height DESC, debut_date ASC;위의 쿼리문은 키를 내림차순으로 정렬을 하는데 키가 같다면 데뷔 날짜를 기준으로 오름차순으로 정렬을 한다.
즉 정렬 기준이 2개이고 첫 정렬 기준은 키, 두번째 정렬 기준은 데뷔 날짜가 되는 것이다.

출력의 개수 제한 : LIMIT
SELECT * FROM member; 로 멤버 테이블을 출력했더니 너무 많다...
그래서 출력의 개수를 제한하려고 한다. 그럴 때 LIMIT를 사용한다.
LIMIT을 사용해 출력의 개수를 3개로 제한해보자.
SELECT * FROM member LIMIT 3;

LIMIT의 형식 : LIMIT 시작,개수 이다.
LIMIT 3으로 할 경우 사실상 0부터 시작하여 3개를 출력하므로
LIMIT 0, 3 인 것이다.

+ 응용을 하여 키(height)를 내림차순으로 정렬하는데 3번째부터 2건만 출력해보자.
SELECT mem_name, height FROM member ORDER BY height DESC LIMIT 3,2 ;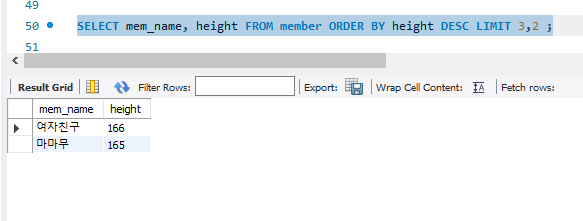
중복된 결과 제거 : DISTINCT
주소만 뽑아 와 보자.
SELECT addr FROM member;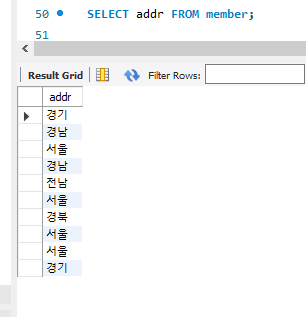
중복되는 주소가 많아 보기가 힘들다.
그래서 일단 정렬을 통해 같은 것들끼리 모아 보기 쉽게 만들자.
SELECT addr FROM member ORDER BY addr;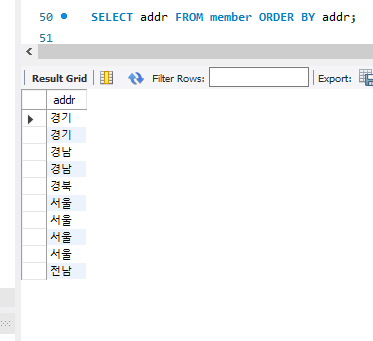
주소들을 보기가 쉬워졌으나, 중복된 것들이 여전히 많아 보기 힘들다.
중복된 것들을 제거하고 보고 싶다.
SELECT DISTINCT addr FROM member;
-> 열 이름 앞에 DISTINCT 만 붙여준다면 중복된 데이터는 제거가 되고 1개만 보여준다.
집계 함수
GROUP BY를 설명하기 전
주로 GROUP BY와 함께 사용되는 함수를 이해하고자 한다.
| 함수명 | 설명 |
| SUM() | 합계를 구합니다. |
| AVG() | 평균을 구합니다. |
| MIN() | 최소값을 구합니다 |
| MAX() | 최대값을 구합니다. |
| COUNT() | 행의 개수를 셉니다. |
| COUNT(DISTINCT) | 행의 개수를 셉니다.(중복은 1개만 인정) |
GROUP BY
: 그룹으로 묶어주는 역할을 한다.
예를 들어 회원(mem_id) 별로 여러 건의 물건을 구매했고, 그것을 출력을 하면 각각의 행으로 표시가 된다.

그래서 같은 회원(mem_id)이 주문한 건수에 대해 모두 합쳐서 출력을 하고 싶다.
위의 예제로 mem_id가 APN인 회원은 1+2+1+1 이므로 5만 출력을 해주면 되는 것이다.
집계 함수를 이용해 구현한다.
SELECT mem_id, SUM(amount) FROM buy GROUP BY mem_id ;
+ 별칭 사용
SELECT mem_id "회원 아이디", SUM(amount) "총 구매 개수" FROM buy GROUP BY mem_id ;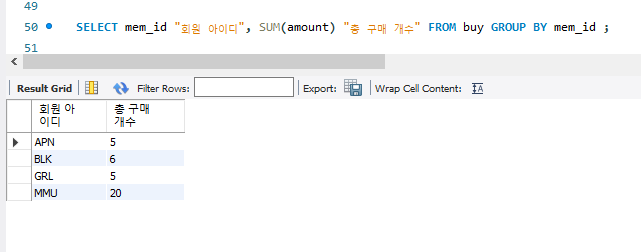
+ 가격(price)와 수량(amount)를 이용해 금액의 총합 구하기
SELECT mem_id "회원 아이디", SUM(price*amount) "총 구매액" FROM buy GROUP BY mem_id ;
+ 전체 회원이 구매한 물품 개수(amount)의 평균
SELECT AVG(amount) "평균 구매 개수" FROM buy;
+ 각각 회원 별 구매한 물품 개수(amount)의 평균
SELECT mem_id, AVG(amount) "평균 구매 개수" FROM buy GROUP BY mem_id;
+ 회원 테이블(member)에서 회원의 수 ( 모든 행의 개수를 셈 )
SELECT COUNT(*) FROM member;
실제로 10개의 데이터가 member에 존재함.
+ 회원 테이블(member)에서 연락처가 있는 회원의 수 ( NULL인 것을 제외 )
SELECT COUNT(phone1) FROM member;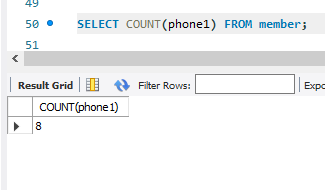
HAVING
앞서 SUM()으로 회원(mem_id)별 총 구매액을 구했다.
여기서 총 구매액이 1000이 넘는 회원만 보고 싶다면
HAVING을 사용한다.
왜? WHERE 을 사용 안 할까? 한번 WHERE을 입력을 해보자.
SELECT mem_id, SUM(price*amount) FROM buy WHERE SUM(price*amount) > 1000 GROUP BY mem_id;
"집계 함수는 WHERE 절에 나타날 수 없다"는 에러가 뜬다.
즉, 집계 함수는 WHERE에 사용할 수 없다는 것이다.
이럴 때 HAVING을 사용해야 한다.
HAVING은 WHERE와 비슷하게 조건을 제한하지만, 집계 함수에 대해서 조건을 제한하는 것이라고 생각하자.
즉, GROUP BY의 조건절은 HAVING을 사용한다.
- HAVING 사용
SELECT mem_id, SUM(price*amount) FROM buy GROUP BY mem_id HAVING SUM(price*amount) >= 1000 ;
-> HAVING 절은 GROUP BY 절 다음에 나와야 한다.
+ 같은 회원은 묶고, 총 구매액 1000이상을 내림차순으로 정렬
SELECT mem_id, SUM(price*amount) FROM buy GROUP BY mem_id HAVING SUM(price*amount) >= 1000 ORDER BY SUM(price*amount) DESC;
모든 내용은 '혼자 공부하는 SQL' 도서를 학습후 정리한 내용입니다.
'프로그래밍 > SQL' 카테고리의 다른 글
| [SQL] MySQL UPDATE, DELETE 사용 설정 방법 (Error Code : 1175) (0) | 2022.06.25 |
|---|---|
| [혼공S] CH.3-2 요약 (0) | 2022.06.25 |
| [혼공S] CH.3-1 요약 (0) | 2022.06.24 |
| MySQL Starting the server 무한 로딩 (0) | 2022.06.24 |
| [SQL] SELECT ~ FROM ~ WHERE + USE, IN(), LIKE, 서브쿼리 (1) (0) | 2022.06.23 |

